

The explosion of technology in the twenty-first century left everyone drowning in a deluge of information. The digital age fundamentally changed how we process information and make decisions. We need AI-assisted problem solving to make better decisions and thrive amidst the tidal wave of data. Traditionally, humans formed a worldview by synthesizing sets of experiences. For example, we learn how to interact with others through childhood play. Recalling the hurt when another stole our toys motivates us to share. We understand how to engage in romantic relationships by watching our parents and romantic comedies. We learn to add and subtract by listening to a teacher’s lectures and working through homework problems.
But, as explained in my first essay in this series, our brains can’t process the billions of bytes of digital data as we did in childhood play. As a result, we need new ways of understanding and applying this wealth of data.
This is the second in my series of essays exploring AI-assisted cognition. I’m developing a machine-learning algorithm to predict 100 bagger stocks. In the previous piece, I discussed traditional analysis by reviewing Christopher Mayer’s popular investment book 100 Baggers: Stocks that Return 100-to-1 and How to Find Them. In this one, I’ll explain the steps needed to create a machine learning assistant to help identify patterns in financial data, specify a data source, and assess its data quality.
The Data Science Process
I read many articles setting out best practice Data Science Life Cycles. I modified two approaches for my project. In the first, Nick Hotz presented one that I like for large organizations, which you can read here. His process includes stakeholder communications and management, problem definition, and considerations when putting Data Science into a production environment. All of that is great for big companies, but most of it doesn’t make sense for this since it’s a personal project. Dr. Cher Han Lau lays out a life cycle specific to the technical tasks required to create a model that you can read about here. But, that approach doesn’t consider strategic objectives. His process works best for a project handed off from management who already thought through the business objectives.
Here’s a Life Cycle I synthesized. It addresses strategic considerations along with technical steps. This type of development is always iterative. Since you don’t know what you don’t know, learning from one step informs and can lead to a reevaluation of previous stages.
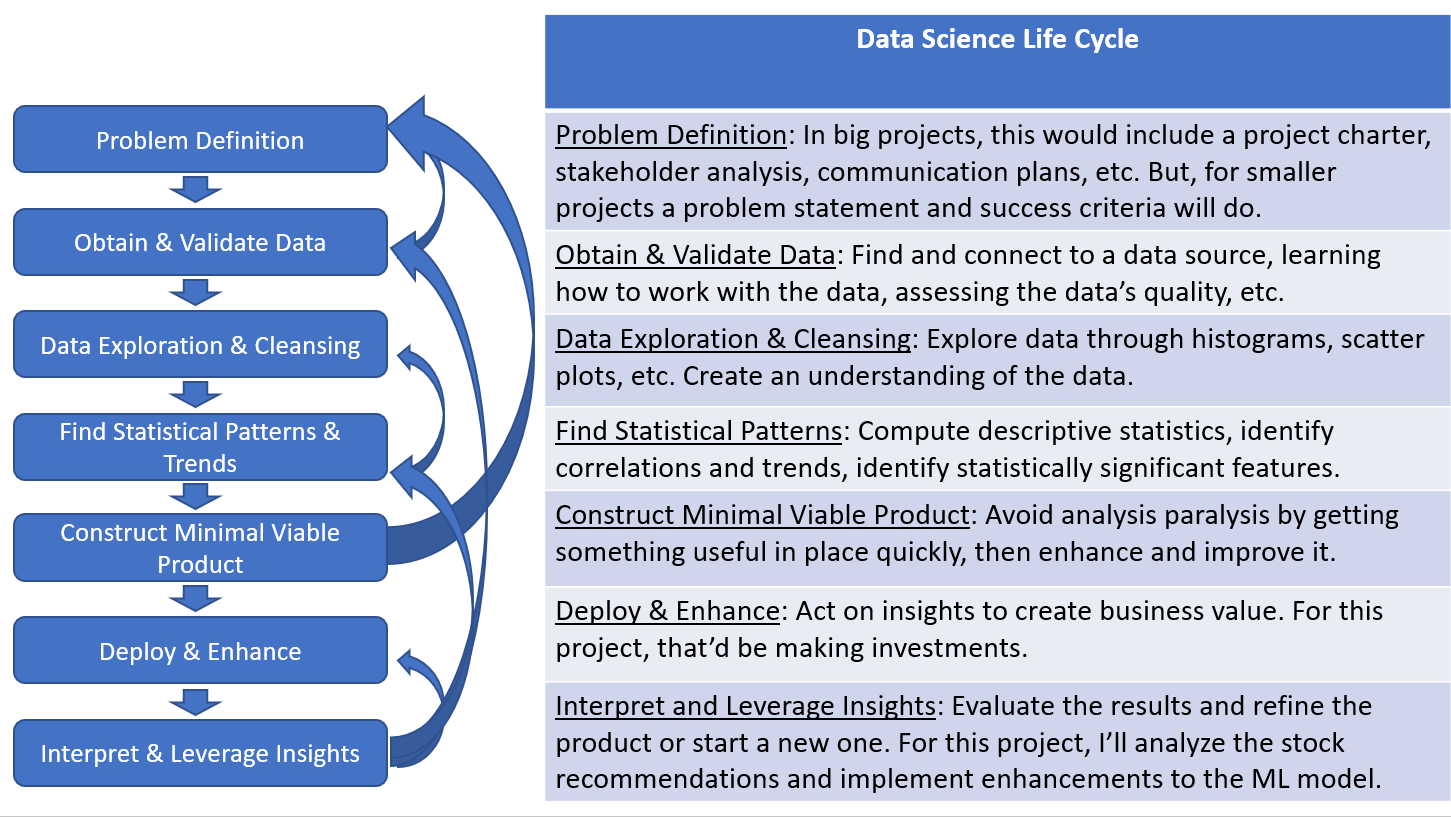
Problem Definition
A problem statement consists of a precise description of the problem and a quantifiable measure of success. For this project, the problem is that we lack a set of features or characteristics to predict 100 baggers, that is, common stocks that return 100 to 1 over a long period of time. I’ll craft a machine learning algorithm using financial data to identify these predictors. First, I’ll split the data set into a Training set and a Test set. The algorithm will learn using the Training data set. Then, I’ll use that algorithm to predict which stocks in Test will eventually become 100 baggers.
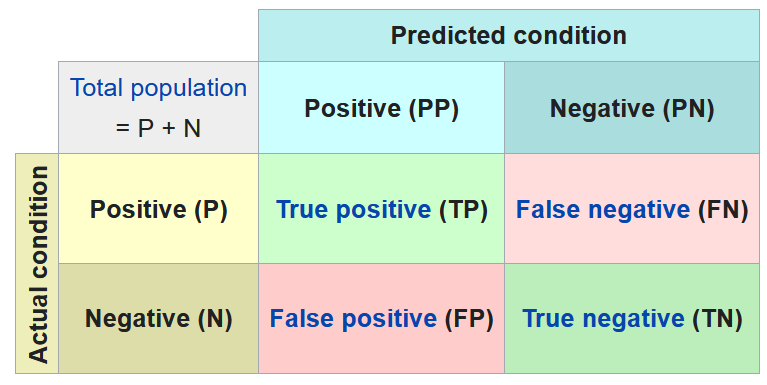
Losing money is a worse outcome than missing a good investment opportunity. So, I’ll select the model that minimizes False Positives. That’s when the model tells me that a stock will be a 100 bagger when it won’t. I’ll also minimize False Negatives when the model fails to predict a 100 bagger. Therefore, accurately predicting a 100 bagger (True Positive or TP in the chart below) or correctly predicting a non-100 bagger (True Negative – TN) as such are ideal outcomes.
The below binary confusion matrix and this YouTube video provide more insight into evaluating machine learning algorithms. Also, I will discuss this at length in my upcoming post on the results of this project.
Data Source
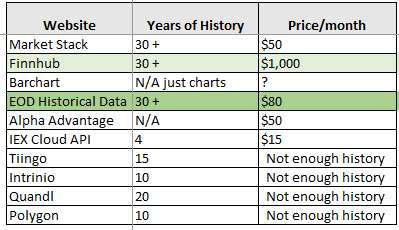
Machine Learning algorithms need data from which to learn, and they need a lot of it – fast. I spent a lot of time researching databases. I wanted to connect using an API over the internet to feed a lot of data into Python easily. Since this study focuses on long-term stock performance, I needed a database with lots of history. I chose EOD Historical Data because it had the best combination of data, price, and documentation. Market Stack had a lot of data and was cheaper than EOD, but the data wasn’t as rich. It didn’t include information about ETFs, Executive Compensation, Currency, Commodities, etc.
Here’s a summary of the data sources I evaluated. I looked at a lot of other characteristics too. Unfortunately, most of these sites didn’t explain their data well. So, my choice boiled down to these factors.
Evaluating Data Quality
Connecting to the EOD Historical Database was a snap. Validating the data proved more difficult. I wrote a script that compares the EOD data to various other data sources. You can find my data quality test script here on this Github Repo. I think it’s so cool that Python can extract data from websites. You can do that in different ways. You can scrape the data, where you try to extract the data shown on a web page. But, that can be problematic if they change the site even a little bit. You can instruct Python to download free data from a website in a CSV or some other format. Then, you can transform it into a Pandas data frame for easy manipulation and accessible to machine learning (ML) algorithms. Here’s a good YouTube on using Yahoo’s free unofficial API. But, there’s only so much free.
I thought at least price data would be standard across data sources. But it’s never exact. Stock prices are often different by a few cents and volume by a few thousand shares. Not the end of the world, but I’m kind of a perfectionist. So, I spent an incredible amount of time signing up for free trials to download data from different sites and writing code to make the comparison. Yahoo Finance is the best free site, but EOD is actually the best I could find. The EOD historical team did a great job of explaining the differences I found and why their data was correct.
Financial Statement Data Quality
Next, I tried to validate the financial statements. That proved exceedingly difficult because each company has its own differentiated financial statements. But, data aggregators transform the raw statements by summing amounts into different labels. As with price data, I compared several data sources. But, it will take a lot of work to analyze each company’s financial statements and validate the information. But that’s just the tip of the iceberg because there are thousands of categories of data and billions and billions of data points in the EOD database. There’s no way I can validate every one of them.
Iterative Process
The above data quality assessment raised important questions, but I need some clarity on what’s important and where I need to focus my analysis going forward. In other words, I can’t get lost in analysis paralysis. I need to narrow down the list of relevant categories; then, I can spend time evaluating the information that matters.
But, after all this work, I’m confident that the EOD database will be a firm foundation for my project. I confirmed it’s the best for price information and seems reasonable for financial statement info. Also, the staff at EOD responded quickly and competently to all my questions. They demonstrated expertise in answering my questions from a coding and finance industry perspective.
After all, this sort of thing always turns into an iterative process. The next steps (from the above chart), Finding Statistically Significant Trends, and creating a Minimum Viable Product will need to loop back into the data quality code once I get a better sense of what data is essential and what’s not. It’s a journey of discovery and exploration. I love that and wouldn’t have it any other way.
What do you think?
Thanks for reading to the end! This blog is my project in the pursuit of truth. I spend dozens of hours researching each blog post, so I hope you found something useful.
Our click-bait culture needs good ideas in an increasingly complex world. That depends on good men and women engaging in intellectually honest discussions, sharing ideas, and challenging each other’s thinking. Writing out my thoughts in detail, along with lots of research, helps me arrive at a more accurate view of truth based on well-documented facts.
If you’d like to support my blog please buy my book. Here’s the link!



Leave a Reply
Your email is safe with us.